Last weekend group of Finnish wikimedians, including me, attended Wikimedia Northern Europe Meeting in Stockholm. Over the years various organisations have been created around Wikipedia: there is the American foundation and different kind of user groups and chapters that want to support the activities of Wikipedists and volunteers in other Wikimedia projects locally. Some of these local organizations are occupied purely by volunteers, while some have also permanent employees or project-related employees.
The WIKINEM participants. I am the one with they grey hat in the first row. Image: Arild Vågen, CC BY-SA 4.0
The highlight of the year in the Wikimedia community is the Wikimania event that brings together both people from different Wikimedia organisations as well as volunteers. In order to get as many people as possible to participate in Wikimania, it has been organised in different parts of the world, most recently in Mexico, Italy and South Africa. Next summer Wikimania will be held for the first time in Northern Europe, Stockholm, and this was one of the most important reasons behind our gathering.
But there are also other reasons why we want to intensify the cooperation between the Nordic countries and the Baltic countries. We are close to each other, both geographically and culturally. Each Wikimedia project has however its own culture and a good example of this is the recent hullabaloo around the English Wikipedia article of Donna Strickland, the Nobel Prize winner. Somebody had tried to create an article for her already in 2014, but it was then removed because of copyright infringement. However e.g. the readers of The Guardian may have thought that Strickland was not considered significant enough for Wikipedia before the Nobel Prize.
Wikipedia editors decide themselves about which subjects they are writing to Wikipedia. This is why there is actually nobody that you can blame if a certain significant person is still missing a Wikipedia article. However, these so called wiki gaps can be influenced for example by organizing editing competitions where editors are producing the missing content together. About 17% of Wikipedia’s articles of people are telling about women, and when almost the same number of editors, 16%, are women, one could imagine that these things are connected.
I think that also the masculine culture of our society should be blamed for the gap. For example if you are asked to make a list of experts in some field, your list can become very manly unless you consciously mind the issue. If you don’t believe this, try asking your acquaintances to name the professionals of a certain field! With help of women-related competitions run by Wikimedia movement the attitude of active Wikipedists for example in Norway has already changed: ”Let’s start by making articles about women’s football players and add men players after them,” they may say now.
Hi, this is a shortened and updated version of our blog post in finnish about our first week of WLM where I explained some of the tech behind the lists. Also most important things at the first. We have received over 1500 photos so far and they are magnificent. If you want to participate you can do it here.
So now about the tech.
Wikidata and SPARQL
In practice the whole system functions, one way or another, on top of Wikidata which we used to record information about the monuments. Then we created lists about them in Wikipedia by listing using SPARQL those subjects that have a National Board of Antiquities id OR are part of a Wikidata item that has one.
You can try out the query here. Run the query by clicking the play button in the lower left hand side of the window. After the results are processed you can choose how the results are displayed from the menu above the results. “Map” and “Image grid” are useful for this query.
Wikipedia lists
The data moves to Wikipedia lists by having ListeriaBot save the lists once or twice a day. As far as Wikipedia is concerned the list is identical to Wikicode. It’s updated dynamically only in small parts. Here’s an example of a list. You can see the whole SPARQL query in the Wikicode. The row template used in the example is implemented by this module.
We have naturally encountered unforeseen problems because we’re doing this for the first time.
One of them is that although it’s possible to use Wikipedia modules for dynamic searches, either our lists were larger than Mediawiki allows or updating it took too long. In both cases Mediawiki left out parts of the page. As a temporary solution we had to save as much as we could pre-formatted. We also simplified our maps, and in case of Helsinki replaced them with links.
We also didn’t prepare for the fact that it isn’t enough to just add data to Wikidata. If you want to refer to the borders of the item on a map, then OpenStreetMap has to have knowledge its Wikidata id. Mostly it didn’t matter but it meant that we weren’t able to add rivers and roads to our Wikipedia maps and we need to do it in the future.
Mobile map
You can see the SPARQL query in the map interface by selecting SPARQL filter from the menu in the upper right hand corner of the map.
In addition to the lists we also used a separate mobile map that’s based Wikishootme. Wikishootme is a mobile map made by Magnus Manske using the Leaflet map library and OpenStreetMap. Items visible on the map are fetched using this SPARQL query. Links that lead to the map include the query as a url parameter.
Saving photos to Wikimedia Commons
Both Wikipedia lists and the mobile map save photos using Wikimedia Commons’ Upload Wizard Campaigns with suitable url parameters. We used these parameters: campaign, description, coordinates, Wikidata id and Wikimedia Commons categories. After the photo has been saved Wikidata id is used for matching it with the data from the National Board of Antiquities.
Next step the Monumental
When we checked our map options in June our options were Monumental and Wikishootme. We selected the latter because it worked nicely with mobile phones and we could add our own SPARQL queries.
WLM beta map (maps.wikilovesmonuments.org) is made on top of Monumental. It uses the P1435 values to get the items that have direct designations to the map. However, items that are part of those monuments aren’t currently included.
The largest editing event by now to Finnish Wikipedia was organized in International Women´s Day in March 8, 2016 in Helsinki Finland under title ”One hundred women into Wikipedia”. Photo:: Teemu Perhiö / CC BY SA 4.0
In 29th August 2016, an article titled Praksiteleen Hermes (Hermes and the Infant Dionysus) was written into Finnish Wikipedia. It was the 400 000th article in this net published encyclopedia.
Among different language Wikipedia, the Finnish Wikipedia ranks in 22nd position based both in the number of articles and the numbers of its active editors (more than five edits a month). If put into perspective of less than six million speakers, Finnish Wikipedia is one of the forefront language editions of Wikipedia.
More than half of the page visitors in Finnish Wikipedia have been mobile users since autumn 2015. This is probably a consequence of long mobile user history and large spread of mobile device in Finland.
This years´ Wikipedia 15th anniversary follows the 15th birthday of Finnish Wikipedia in February 2017. Next year Finland will celebrate her 100th year of independence. The community of Finnish Wikipedia will celebrate this by translating one hundred most central articles concerning Finland into other languages. In 2017, an international translation competition will be launched, where we expect participants from tens of different language Wikipedia.
The contents of Finnish Wikipedia have also been developed in collaboration with cultural and memory organizations. More than hundred people participated in a Wikipedia editing event in March International Womens´ Day in Helsinki, creating articles of women. Editing events if Finland have been organized in many parts of the country, in Pori, Oulu and Rovaniemi.
Wikimedia Suomi, a chapter of Wikimedia Foundation, is an association that backs up the volunteer driven net publication and their sister forums. The non-profit association that is funded by the Foundation, organizes, coordinates and promotes various Wikimedia related events. Among them is a study of Wikipedia, where experience, motives, styles and groups of Wikipedia readers and editors are researched.
Wikipedia and public service broadcasters have quite a similar mission. We both provide information for the public. One project is encyclopedic by its nature, the other journalistic. But both strive to document the world, as it was yesterday, as it is today and as it unfolds towards the future.
The Finnish Broadcasting Company, Yle, has since April 1st 2016 tagged our online news and feature articles with concepts from Wikidata. This was a rather natural next step in a development that has been ongoing within Yle for several years now. But it is still an interesting choice of path for a public service media company.
With linking journalistic content and the wiki projects to each other in machine-readable format, we hope to gain win-win situations where we can fulfill our missions even better together.
Why Wikidata?
The short answer to why is, because Freebase is shutting down. We have since 2012 tagged our articles using external vocabularies. The first one we used was the KOKO upper ontologyfrom the Finnish thesaurus and ontology service Finto. KOKO is an ontology that consists of nearly 50 000 core concepts. It is very broad and of high semantic quality. But it doesn’t include terms for persons, organizations, events and places.
Enter Freebase. We originally chose Freebase it 2012 quite pragmatically over the competition (Geonames, Dbpedia and others) mainly because of its very well functioning API interface. When Google in December 2014 announces that it would be shutting down Freebase we had to tackle this situation in some way.
The options were either to use Freebase offline and start building our own taxonomy for new terms, or to find a replacing knowledge base. And then there was the wild card of the promised Google Knowledge Graph API. The main replacing options were DBpedia and Wikidata, no other could compete with Freebase in scope.
Some experts said that the structure and querying possibilities in Wikidata where subpar compared to DBpedia. But for tagging purpose, especially for the news departments, it was far more important that new tags could be added either manually by us ourselves or by the Wikipedians.
During 2015 there really seemed to be a lot of buzz going on around Wikidata and inside the community. And when we contacted Wikimedia Finland we were welcomed with open arms to the community, and that also made all the difference. (Thank you Susanna Ånäs!) So with the support of Wikimedia and with their assurance that Yle-content fulfilled the notability demand we went ahead with the project.
Migration
In October 2015 we had tagged articles with 28 000 different Freebase concepts. Out of those over 20 000 could be directly found with Freebase-URIs in Wikidata. For the additional part, after some waiting for the promised migration support from Google, we started to map these together.
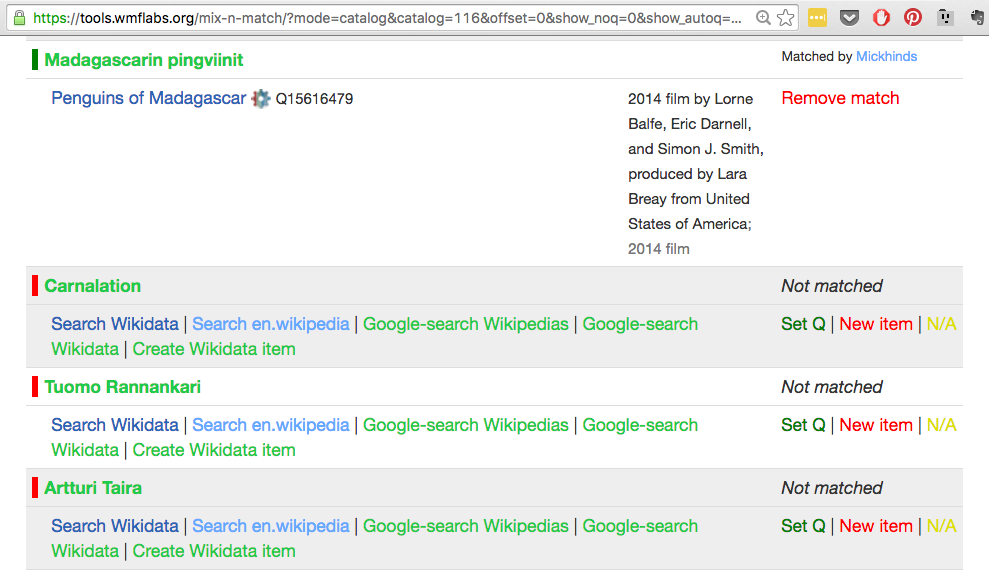
We got help from Wikidata to load them up to the Mix’n’match-tool. (Thank you Magnus Manske!) And mapped an additional 3800+ concepts. There are still 3558 terms unmapped at the time of writing, so please feel free to have a go at it.https://tools.wmflabs.org/mix-n-match/?mode=catalog&catalog=116#the_start
Mix and Match-tool.
At the time of transition to Wikidata in April 2016 our editors had been very diligent and managed to use 7000 more Freebase concepts. So the final mapping still only covered around 72% of the Freebase terms used. But as we are using several sources for tagging, this is an ongoing effort in any case, and not a problem for our information management.
Technical implementation
We did the technical integration of the Wikidata annotation service in our API-architecture at Yle. Within it we have our “Meta-API” that gathers all the tags used for describing Yle-content. When the API is called it returns results from Wikidata, KOKO and a third commercial source vocabulary we are using. Since those three vocabularies overlap partially they need to be mapped / bridged to each other (e.g. country names can be found in all three sources). The vocabulary is maintained under supervision of producer Pia Virtanen.
The API-call towards Wikidata returns results that have labels in at least Finnish, Swedish or English. Wikidata still lacks term descriptions in Swedish and Finnish to a rather high degree, so we also fetch the first paragraph from Wikipedia to provide disambiguation information to the editors that do the annotation.
The Meta-API is then implemented in the CMSs. For example in the Drupal7 sites widely used within Yle we have an own module, YILD https://www.drupal.org/project/yild, which can be used for tagging towards any external source.
The UX encourages a workflow where the editor first inserts the text, and then manually chooses a few primary tags. After that they can by pushing a button fetch automatic annotation suggestions, which returns approximately a dozen more tags. From these the editor can select the suitable ones.
The tags are then used in the article itself, they create automatic topical pages, are used in curated topical pages as subject headings and navigation, and bring together Yle-content produced in different CMSs and organizational units in different languages. They are used in our News app Uutisvahti/Nyhetskollen. And the tags are also printed out in the source code according to schema.org specifications, mainly for SEO.
The opening of Yle’s APIs are on the road map for Yle’s internet development. Once we can provide this metadata together with data about our articles and programs, third party developers can build new and specialized solutions for specific uses and audiences.
One suggested application would be to build a “Wikipedia source finder”. So that if a Wikipedian finds a stub article, they could look up what material Yle has about the topic, and complete the article with Yle as a source.
Wikidata for annotation
We still at the time of writing only have a couple of weeks experience with annotating our content using Wikidata. Compared to Freebase there seems to be far more local persons like artists and politicians, as well as more local places and events.
For breaking news stories the Wiki-community is of great help. In a sense the wiki-community is crowdsourcing new tags. For example events like the 2016 Brussels bombingsor the Panama papers leakget articles written very fast after the events have taken place. Thus creating a Wikidata-item, and a tag for us. This also gives the added benefit of a normalized label and description for the events.
In Norway several media companies, including our fellow broadcaster NRK, have initiated collaboration in specifying how important news events could be called in a unified and homogenous way. During the tragic attacks in Norway in 2011there were over 200 different labels created and used in media for this event during the first day.
Through Wikidata we can normalize this information for all the languages we use, Finnish, Swedish and English. And we have the option to expand to any of the dozens of languages active in the Wiki-projects.
Wikidata and public service
Apart from all the technical factors that fulfil their tasks, there is another side to using Wikidata as well. It feels that the Wiki-projects and public service companies have a lot in common in their ethos and mission, but not too much to be in a competitive relationship. The web is increasingly a place of misinformation and commercial actors monetizing on user data. It feels in accordance increasingly important to tie independent public service media, to the free-access, free-content information structure built by the public that constitutes the wiki projects. As content becomes more and more platform agnostic and data driven, this strategy seems a good investment for the future of independent journalism.
Last week I participated Wikidata event on Yle’s Iso paja. After the long and very interesting day I had a chance to make a very quick video interview with one of our Swedish guests. Henrik Summanen works as a development manager at Swedish National Heritage Board and he was very satisfied with the Wikipedian in residence project they did 3 years ago. So this is to encourage you GLAMs – go and start! Read more about WIR projects.
Final results are counted from the post it notes. On the right side the three stages of editing are presented on columns; editors are on the rows. Teemu Perhiö CC BY-SA 2.0
The Museum of Contemporary Art Kiasma held a new-kind-of editathon event, ”Wikitriathlon”, on 28 March. Like a real triathlon the event was a multi-stage competition involving three stages of editing: writing an article, editing an existing article and adding links to articles. The game was fair and in the end everybody was awarded the ”first prize”.
There were lots of source material for writing the articles! Teemu Perhiö CC BY-SA 2.0
The staff of Kiasma had hoped that the participants would edit articles related to the artists presented at the exhibitions. At the end of the day 14 new articles were created and 18 existing articles complemented. There were both newcomers and experienced wikipedians present. Hopefully many of the newcomers will stay active and edit articles in the future as well!
In addition to the triathlon model, new approaches to presenting and monitoring the results were tried out. Edits were written on post it notes that were attached to white boards. This way the editors got a better sense of the progression made during the day and could more easily realise their impact on Wikipedia. Participants could also ”book an article” by attaching their own name on top of the article name on a whiteboard. Maybe not so modern approach, but it worked (due to the limitations of the wiki software, more than one people can’t edit a wiki page at the same time).
The Kiasma building had just been renovated, and during the break the participants got a free tour of the new exhibitions Face to Face & Elements. 2013 Kiasma held a ”Wikimarathon”, a 24-hour editathon; this year a Wikitriathlon. Maybe next time we will see a pentathlon-themed event?
Participants editing articles. On the background there are whiteboards for booking articles. Teemu Perhiö CC BY-SA 2.0
Course participants editing Wikipedia at the first gathering at the Finnish Broadcasting Company Yle.
Bring Culture to Wikipedia editathon course is already over halfway through its span. The course, co-organised by Wikimedia Finland, Helsinki Summer University and six GLAM organisations, aims to bring more Finnish cultural heritage to Wikipedia.
The editathon gatherings are held at various organisation locations, where the participants get a ”look behind the scenes” – the organisations show their archives and present their field of expertise. The course also provides a great opportunity to learn basics of Wikipedia, as experienced wikipedian Juha Kämäräinen gives lectures at each gathering.
Yle personnel presenting the record archives.
The first course gathering was held at the Archives of the Finnish Broadcasting Company Yle on 2nd October. The course attendees got familiar with the Wikipedia editor and added information to Wikipedia about the history of Finnish television and radio. The representatives of Yle also gave a tour of the tape and record archives. Quality images that Yle opened earlier this year were added to articles.
Course attendee Maria Koskijoki appreciated the possibility to get started without prior knowledge.
”The people at Yle offered themes of suitable size. I also got help in finding source material.”
Cooperation with GLAMS
Finnish National Gallery personnel presenting sketch archives at the Ateneum Arts Museum.
There are many ways to upload media content to Wikimedia Commons. One of the new methods is using GLAMWiki Toolset for batch uploads. Wikimedia Finland invited the senior developer of the project, Dan Entous, to hold a GW Toolset workshop for the representatives of GLAMs and staff of Wikimedia Finland in Sebtember before the beginning of the course. The workshop was first of its kind outside Netherlands.
Course coordinator Sanna Hirvonen says that GLAM organisations have begun to see Wikipedia as a good channel to share their specialised knowledge.
“People find the information from Wikipedia more easily than from the homepages of the organisations.”
This isn’t the first time that Wikimedians and culture organisations in Finland co-operate: last year The Museum of Contemporary Art Kiasma organised a 24-hour Wikimarathon in collaboration with Wikimedia Finland. Over 50 participants added information about art and artists to Wikipedia. Wiki workshops have been held at the Rupriikki Media Museum in Tampere and in Ateneum Art Museum, Helsinki.
Wikipedian guiding a newcomer at the Ateneum Arts Museum.
For a very long time Finland was part of Sweden. Maybe that explains why the Finns now always love to compete with Swedes. And when I noticed that Swedish Wikipedia is much bigger than the Finnish one I started to challenge people in my trainings: we can’t let the Swedes win us in this Wikipedia battle!
I was curious about how they did it and later I found out they had used ”secret” weapons: bots. So when I was visiting Wikimania on London on August I did some video interviews related to the subject.
First Johan Jönsson from Sweden tells more about the articles created by bots and what he thinks of them:
Not everyone likes the idea of bot created articles and also Erik Zachte, Data Analyst at Wikimedia Foundation shared this feeling in the beginning. Then something happened and now he has changed his view. Learn more about this in the end of this video interview:
Now I am curious to hear your opinion about the bot created articles! Should we all follow the Swedes and grow the number of articles in our own Wikipedias?
GLAMWiki Toolset project is a collaboration between various Wikimedia chapters and Europeana. The goal of the project is to provide easy-to-use tools to make batch uploads of GLAM (Galleries, Libraries, Archives & Museums) content to Wikimedia Commons. Wikimedia Finland invited the senior developer of the project, Dan Entous, to Helsinki to hold a GW Toolset workshop for the representatives of GLAMs and staff of Wikimedia Finland on 10th September. The workshop was first of its kind outside Netherlands.
GLAMWikiToolset training in Helsinki. Photo: Teemu Perhiö. CC-BY
I took part in the workshop in the role of tech assistant of Wikimedia Finland. After the workshop I have been trying to figure out what is needed for using the toolset from a GLAM perspective. In this text I’m concentrating on the technical side of these requirements.
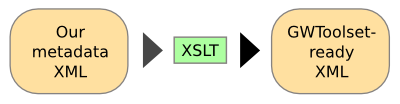
What is needed for GWToolset?
From a technical point of view, the use of GWToolset can be split into three sections. First there are things that must be done before using the toolset. The GWToolset requires metadata as a XML file that is structured in a certain way. The image files must also be addressable by direct URLs and the domain name of the image server must be added to the upload whitelist in Commons.
The second section concerns practices in Wikimedia Commons itself. This means getting to know the templates, such as institution, photograph, artwork and other templates, as well as finding the categories that are suitable for uploaded material. For someone who is not a Wikipedian – like myself – it takes a while to get know the templates and especially the categories.
The third section is actually making the uploads by using the toolset itself, which I find easy to use. It has a clear workflow and with little assistance there should be no problems for GLAMs using it. Besides, there is a sandbox called Commons Beta where one can rehearse before going public.
I believe that the bottleneck for GLAMs is the first section: things that must be done before using the toolset. More precisely, creating a valid XML file for the toolset. Of course, if an organisation has a competent IT department with resources to work with material donations to Wikimedia Commons, then there is no problem. However, this could be a problem for smaller – and less resourceful – organisations.
Converting metadata in practise
Like I said, the GWToolset requires an XML file with a certain structure. As far as I know, there is no information system that could directly produce such a file. However, most of the systems are able to export metadata in XML format. Even though the exported file is not valid for GWToolset, it can be converted into such with XSLT.
XSLT is designed to this specific task and it has a very powerful template mechanism for XML handling. This means that the amount of code stays minimal compared to any other options. The good news is that XML transformations are relatively easy to do.
XSLT is our friend when it comes to XML manipulation.
In order to learn what is needed for such transforms with real data, I made couple of practical demos. I wanted to create a very lightweight solution for transforming the metadata sets for the GWToolset. Modern web browsers are flexible application platforms and for example web-scraping can be done easily through Javascript.
A browser-based solution has many advantages. The first is that every Internet user already has a browser. So there is no downloading, installing or configuring needed. The second advantage is that browser-based applications that use external datasets do not create traffic to the server where the application is hosted. Browsers can also be used locally. This allows organisations to download the page files, modify them, make conversions locally in-house, and have their materials on Wikimedia Commons.
XSLT requires of course a platform to run. There is a javascript library called Saxon-CE that provides the platform for browsers. So, a web browser offers all that is needed for metadata conversions: web scraping, XML handling and conversions through XSLT, and user interface components. Of course XSLT files can also be run in any other XSLT environment, like xsltproc.
Demos
Blenda and Hugo Simberg, 1896. source: The National Gallery of Finland, CC BY 4.0
The first demo I created uses an open data image set published by the Finnish National Gallery. It consists of about one thousand digitised negatives of and by Finnish artist Hugo Simberg. The set also includes digitally created positives of images. The metadata is provided as a single XML file.
The conversion in this case is quite simple, since the original XML file is flat (i.e. there are no nested elements). Basically the original data is passed through as it is with few exceptions. The “image” element in original metadata includes only an image id, which must be expanded to a full URL. I used a dummy domain name here, since images are available as a zip-file and therefore cannot be addressed individually. Another exception is the “keeper” element, which holds the name of the owner organisation. This was changed from the Finnish name of the National Gallery to a name that corresponds to their institutional template name in Wikimedia Commons.
Photo: Signe Brander. source: Helsinki City Museum, CC BY-ND 4.0
In the second demo I used the materials provided by the Helsinki City Museum. Their materials in Finna are licensed with CC-BY-ND 4.0. Finna is an “information search service that brings together the collections of Finnish archives, libraries and museums”. Currently there is no API to Finna. Finna provides metadata in LIDO format but there is no direct URL to the LIDO file. However, LIDO can be extracted from the HTML.
The LIDO format is a deep format, so the conversion is mostly picking the elements from the LIDO file and placing them in a flat XML file. For example, the name of the author in LIDO is in a quite deep structure.
These demos are just examples, no actual data has yet been uploaded to Wikimedia Commons. The aim is to show that XML conversions needed for GWToolset are relatively simple and that in order to use GWToolset the organisation does not have to have an army of IT-engineers.
The demos could be certainly better. For example, the author name must be changed to reflect the author name in Wikimedia Commons. But again, that is just a few lines in XSLT and that is done.
During 15-16 September Finnish open knowledge and open data practitioners gathered in Helsinki at the Open Finland 2014 event. Wikimedia Finland participated with a joint exhibition stand together with the Finnish OpenGLAM network. We presented the various Wikimedia projects from different standpoints. The GLAM activities were also showcased with the Open Cultural data course’s recently published online contents. Wikimedia participated also at the Finnish eLearning Centre’s exhibition stand.
The main purpose of the Open Finland event was to showcase different open data projects and to encourage civil servants to open up their contents. Open knowledge is clearly valued by the Finnish government, demonstrated by the fact that the event was organised by the Prime Minister’s Office. PM Alexander Stubb was also present and gave the opening speech at the event.
What can Wikimedia offer to public sector organisations? Wikimedia does open knowledge on a practical level. Wikimedia projects Wikipedia and the media file repository Commons are already well-known international and multilingual platforms. With these platforms cultural heritage organisations and government offices can open up and link their own data. Wikimedia is non-profit and its pages are ad-free. This autumn Wikimedia Finland organises Wikipedia education together with Finnish cultural heritage institutions.
Wikidata is a new way to open machine-readable structured data for free use. Wikidata is becoming a comprehensive linked database that includes data used by Wikipedia and other Wikimedia projects. For civil servants and researchers it would be useful to use Wikidata as a reference tool. It will be utilised for example in the British ContentMine project that uses machines to mine and liberate facts from scientific literature. This autumn Wikimedia Finland will organise a Wikidata workshop. If you are interested, please sign up here!
Historical maps are an excellent example how governmental and cultural heritage institutions can partner with non-profit organisations. Wikimaps is an initiative by Wikimedia Finland to gather old maps in Wikimedia Commons, place them in world coordinates with the help of Wikimedia volunteers and start using them in different ways. The project brings together and further develops tools for the discovery of old maps and information about places through history. At the Open Finland event Wikimedia was not the only participating organisation that is dealing with old maps. For example Helsinki Region Infoshare and the National Land Survey of Finland have a wealth of historical maps and other geospatial open data, and some of them have already been published online free of charge.
Wikimedia Finland exhibition stand. Image: Kimmo Virtanen. CC-BY.
At the event there was a clear desire that digitalisation and opening up government data would lead to new kind of entrepreneurship and thus to economic growth. Indeed there were interesting product launches, such as Nearhood which brings together news and other information related to a specific neighbourhood, or the environmental data project Envibase by the Ministry of the Environment.
Demonstrating the societal value of open data has been somewhat difficult. This is especially common in cultural heritage projects where in many cases there are no tangible financial benefits. Beth Noveck, one of the event’s keynote speakers, emphasised the need to search for evidence about the societal and financial value of open data. So far the arguments supporting open data have been too heavily based on faith, not evidence. Noveck displayed many projects in the UK and in the United States. Perhaps these examples could offer good ideas to circulate in Finland too.
Personal data was one of the key topics during the event. The MyData panelists pondered about the citizens’ possibilities and limitations to use data about themselves. Open Knowledge Finland has also published a report about the topic. Personal data is an interesting topic that raises differing opinions. On the one hand the public opinion is clearly in favour of individuals’ right to control data about themselves. On the other hand for example the Wikimedia Foundation has clearly criticised the recent “right to be forgotten” European Union legislation because it can lead to censorship that distorts online source material.
Wikimedia Finland would like to thank Samsung for lending us IT equipment for exhibition use.











.jpg)
.jpg)